v2019.04.24
You save files onto Forever Bucket. Forever Bucket serves them to the public forever. You pick what is important to share with the future. We can’t make the future care, but you can decide what to preserve.
The idea here is simple, we want to store data forever. Not ten years, not a hundred years, but forever. The conventional wisdom is that no digital media lasts forever and that is correct. That is why it needs to be curated by an organization who can preserve it across time and copy from one media to another as technology changes and components fails, verifying checksums and hashes as they go to make sure it is exactly intact, complete and correct.
The reasons for doing this are varied and likely personal to each user. I can’t say why or if you’d want to use it, I’m not your boss. We live our lives increasingly digital but we are pretty bad about preserving things. News sites get purchased or change technology and suddenly the new content management system breaks all the links or old articles just disappear.
There are some big risks that we can’t do much about, but we can try.
The basic financial plan is to invest most of the income such that the price is enough to pay the costs of storing the data in question forever. That is why the prices are as high as they are. Our financial modeling assumes a rather conservative rate of return on investment of 3% per year.
The plan requires the ability to invest money and earn a return on that investment and ideally have the investment grow while extracting some sort of dividend to pay ongoing costs. Since the birth of capitalism this has been true but there is no guarantee that this will remain true. In order to be able to bridge time periods of economic decline we are planning on fairly pessimistic return numbers so should be able to survive any recession or depression that isn’t much larger than ones that have occurred historically. Additionally, we can survive much worse economic conditions by hibernating as needed. The most obvious method would be to abandon having the data available for download for a time, since the online storage and hosting is the most expensive cost.
The plan does not depend on decreasing costs of technology. Costs will probably continue to decrease but we are not depending on that. At some point we will probably not be able to pack bits or gates any tighter and that is fine. The risk is that we will have a technological decline. If storage gets more expensive or harder to acquire that might be a problem. We can hopefully bridge any temporary declines with things like m-discs which according to the marketing should be readable for 1000 years.
The current architecture using Google Cloud for online web serving then AWS S3 Glacier as a backup storage location. Each of these solutions is backed by a great deal of professional storage knowledge, monitoring, redundancy and security. Each one is fault tolerant to the point of entire data centers buildings burning down without losing data. Using both providers would be a good solution for any reasonable operation. So we go further. In addition we store on hard drives that are stored offline after they are filled and M-Discs which are sent to three separate locations for storage.
This is the current setup and will change over time as prices and offerings and media change. We don’t aim to be the first on anything new, we prefer cloud providers who have at least a decade of history and storage media that is equally proven.
When the first create a snapshot, it is copied from your Dropbox onto Google Cloud Storage. While doing that, we check the checksum provided by dropbox and compare it do the data actually read. At the same time we compute several other forms of checksum used by other providers. That way, we have a hash equivalence mapping and can know the data is copied faithfully across forms. With the snapshot we create a manifest which lists all the files in the snapshot, their paths and their hashes. This manifest becomes the source of truth for the snapshot. Every time we copy the files we check the manifest to make sure we have them all and the hashes come out the same so that any change would be detected.
When you save the snapshot, we copy it to AWS S3 and to hard drives at one of our physical sites. The snapshot is also saved to be burned to M-Discs once we have enough data for a batch of them. The hard drives are stored offline and the M-Discs are distributed to our three physical sites across the country.
For cloud security, the AWS account used is protected by 2-factor auth and there are no AWS keys that exist that have delete permissions on the S3 data. This prevents accidental deletes. To prevent data from being overwritten, the S3 buckets have versioning turned on, so even if a run-away process somehow overwrites the data with incorrect or incomplete data, S3 will preserve the previous versions.
On the Google Cloud side, there is no code in the project that deletes things from Google Cloud Storage so there is no risk of a process going wrong and deleting data it shouldn’t.
And even if all that went wrong, we have the physical hard drives and M-Discs stored offline.
This is only the current setup. Things will certainly change as time goes on. While we will never claim to have data storage that we don’t in fact have, we reserve the right to not disclose all of our media and repositories as an additional layer of protection.
A person lives for a finite amount of time. Trusts have limited durations due to limits to prevent perpetuities. However, a corporation may exist for as long as someone is willing to file and there is some government to file with. Forever Bucket is a Corporation in the state of Washington. The hope is that the corporation will have enough assets that it not only pays its own expenses but also has some to pay dividends to shareholders. Hopefully enough that the shareholders want to keep it going.
I think it also makes sense for a small, single purpose organization to tackle this. With larger corporations there is always a temptation to separate the assets from the liability in order to make a quarter look better or get through a lean time or just line someone’s pocket. With a smaller, focused organization it would be very hard to hide or disguise something like that.
Forever Bucket uses the following services as integration points:
The top level of a repository of data is an archive. You create an archive with some name and then it will be reached with a URL that looks like:
https://archive.foreverbuck.com/<archive>
https://1209a.com/<archive>
When you create an archive, a directory gets created in your linked Dropbox account, app/ForeverBucket/<archive>. You put files there to be part of the archive. After placing files there, wait for dropbox to sync and then on the Forever Bucket website click “Scan” to quickly see if the expected files are there or “Create Snapshot” to create a snapshot.
A snapshot is a point in time copy of all the files in the dropbox directory for that archive.
Once the snapshot is created, you can view it in a web browser and then save it or discard it. Once you save that snapshot, it is permanent. It can’t be removed or modified and pretty soon it will be written to hard drives in strange places and burned onto M-Discs.
You can create additional snapshots. The snapshots share storage with each other, so you won’t use storage quota for files that are exactly the same between snapshots (even if you rename them or move them around within the archive). If they have the same bytes, the system sees them as the same file (even if it has a different name).
Each snapshot that is saved will be reachable at a URL like: https://archive.foreverbucket.com/<archive>/<snapshot>
Rather than a particular snapshot, using ‘head’ in place of the snapshot id will always point to the most recent saved snapshot.
https://archive.foreverbucket.com/<archive>/head
To store data you need storage quota. Storage quota is used for the files in snapshots and the snapshot manifests, which is a file generated for each snapshot that describes the files in the snapshot, their hashes and location.
The other type of quota is transfer quota and is used when people download files from your archives. There are two types of transfer quota, one time and refreshing. The one time quota is an amount that gets used and is gone. The refreshing quota slowly refills over the course of a year.
You start with 10MB or storage, 10MB of refreshing transfer, and 50MB of one time transfer.
More of each type or bundles may be purchased. Note: none of the options are recurring expenses. You pay once and get the quota forever in the case of storage or refreshing transfer. The one time transfer remains until it is used. If the refreshing transfer is not used, it accumulates with no limit.
If your archives exceed your available transfer quota, they are temporarily disabled and requests to them return errors. They will automatically be enabled again when your transfer quota returns to positive. Or of course, you can buy more quota.
For any directory that has an index.html, that will be served on access to that directory. Otherwise, we will generate an extremely rudimentary index page that simply links to the files and subdirectories in that directory.
In addition, we automatically generate a BitTorrent torrent file for each snapshot. This torrent includes a Web Seed so Forever Bucket will always seed your torrent (subject to available transfer quota). Since torrent users will download from each other in addition to the web seed, this is a great way to distribute things without using a lot of bandwidth.
After a snapshot is created but before you hit “Save” it is just on Google Cloud Storage:
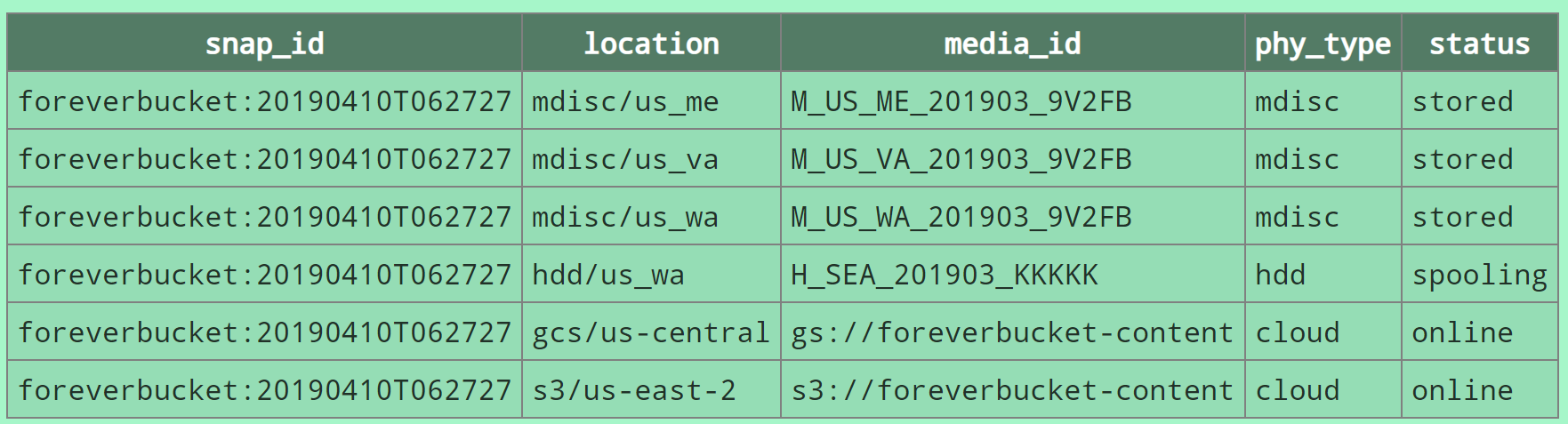
After you press “Save” on a snapshot, it will be replicated to additional locations. In a few minutes, depending on size and number of files it should reach a few additional locations, shown under “Details” for the snapshot:
After some days or weeks it will be in even more locations, as the M-Discs are stored in remote locations:
Forever Bucket is a data storage and hosting tool. As such, snapshots shared with this service are intended to be public. Do not share with Forever Bucket anything you do not wish to make public.
Your name, email address and any other personal information we have about you are private. We will not share them. We in fact try to avoid collecting anything we don't strictly need. We will only use your email send things related to your account.
An purchased plan will refunded completely within 1 year of ordering if you are not satisfied. We would like to know what, but that isn’t required. There are two exceptions:
We make the following guarantee. If a snapshot is saved within our system, after 30 days it will be considered hardened. If we can not produce the data for a hardened snapshot within 30 days of a request, you will be owed 10 times the amount paid for that storage. That is the limit of liability for our services.
We do not make any guarantees on availability, meaning the ability for a user to retrieve the snapshot via HTTP or HTTPS. We operate on a best-effort basis for that. However, the system is architected to be highly available and fault tolerant. We expect an availability of roughly 99.9% (roughly 8 hours of downtime per year).
Forever Bucket was founded in 2018 by Joseph Gleason in Seattle, WA, US. Mini resume:
I have a strong background in distributed systems and especially high availability architecture.
These are features we don’t have yet but plan on adding.
In this mode, you set a date and the archive will not be readable by anyone until that date. You can set the date as far into the future as you like. You can change the date, but only increase it. This way, you can use this feature as an effective dead-man’s switch.
We plan on supporting other upload methods. They might include being able to upload a zip or tar file (up to a certain size). S3 or Google Cloud Storage buckets.
How to transfer collections of files remains a not well solved problem: XKCD: File Transfer
We plan on supporting an archive type where rather than uploading files you set the archive to mirror an existing repository of data. Examples might be a GitHub repo or an Instagram account.